



Problem Statement
Credit card fraud is one of the most serious challenges facing businesses today, and credit card fraudsters use a variety of techniques to conduct fraud. Credit card fraud is described as when a person uses another person’s credit card for personal reasons while the owner of the card and the card issuer are unaware. Furthermore, the person using the card has no relationship to the cardholder or issuer, and has no intention of contacting the cardholder or repaying the purchases made. An act of criminal deception or deceiving with the intent to use an unlawful account and/or personal information, illegal or unauthorized use of account for personal gain, and misrepresentation of account information to get goods and/or services are all examples of credit card fraud.
The victim of credit card fraud stands to lose a lot more than just the money. In many situations, it takes more time to repair the harm to a person’s credit that has been wrecked by fraud, not to mention the unwanted length of time it takes to get back on track. Hapless businessmen become the victims of fraud and lose money as a result. Fraud can take numerous forms, including the loss of a credit card or the perpetrator’s use of other fraudulent applications.
According to the Association of Certified Theft Examiners (ACFE), credit card fraud has surpassed $1 billion and is on the rise. It is estimated to reach $3 billion in the United States alone by the end of 2007. The availability of online purchasing has sparked new concerns. The popularity of online buying is growing, with spending up 22% in 2005 compared to 2004. In 2005, total internet expenditure reached $143.2 billion, with surveys indicating that nearly 90% of all internet purchases are made with a credit card. Approximately 5% of all internet purchases are fraudulent. The lack of face-to-face connection with the fraudster makes the internet particularly vulnerable to fraud, as it allows for greater anonymity and makes prevention and detection more difficult (Barker et al., 2008).
Businesses, despite popular assumption, are significantly more vulnerable to credit card theft than consumers. While consumers may have difficulty getting a malicious payment refunded, retailers lose the cost of the product sold, incur reversal costs, and take the chance their bank account being terminated. The retailer (the online site) is no longer secured with benefits of confirmation such as signatory check, picture verification, and so on, therefore the card not present scenario, such as shopping on the internet, offers a higher hazard. In fact, performing any of the ‘tangible’ checks required to determine who is on the other end of the transaction is nearly difficult. For fraudsters, this makes the internet incredibly appealing. According to a recent survey, cyber fraud is 12 to 15 times more common than ‘real-world’ fraud (Bhatla et al., 2003).
To address this problem, this proposal aims at solving this problem by analysing a card and it’s spending behaviour and the finally classifying the transactions taking place through the card as legitimate or fraudulent transactions.
Intended Users
It is common knowledge that credit card fraud is on the rise. Annually, numerous siphon, forgery, and scamming operations happen and usually cost corporations and victims billions of dollars. Despite the fact that credit card companies and retailers have taken a variety of measures to combat credit card fraud, it remains a worry. Because so many individuals possess credit and debit cards and use them on a regular basis, more precautions must be taken to prevent and detect this form of fraud. Credit card fraud has become a major problem that must be addressed.
While there is no way to totally eliminate this form of fraud, credit card providers, retailers, and customers can all take measures to protect oneself.
Financial fraud is a potential threat in the finance industry, enterprises, and government, with much more effects. Fraud is described as illegal deceit with the goal of obtaining monetary benefit. Credit card transactions have surged as a result of the high reliance on internet technologies. Detecting fraudulent transactions using traditional human methods is time-consuming and inefficient, therefore the introduction of big data has rendered manual approaches obsolete. Financial institutions, on the other hand, have focused their emphasis on current computational approaches to address the problem of credit card fraud.
Previously, the financial institutions have been using traditional and manual methods for fraud detection. These methods include developing deterrent tools. These tools are such as chip-based cards, making skimming and equipment for faking cards harder to obtain, providing training to the businessmen and customers on how to spot counterfeit cards. However, with the advancement in the cyber and computer technologies, the fraudsters have become wiser too and are using the technology to their advantage too. The availability of more users in banks mean there is a large lake of data to be exploited by the criminals but also, the banks and financial institutions could take advantage of this to create algorithms that are able to learn from the data and be able to tighten their defences in turn.
This proposal aims at benefiting aspiring financial institutions on the methods they can employ to move from the traditional and manual methods of fraud detection to modern, robust and technologically advanced methods for detecting fraud in the transactions. If the methods are implemented, then the customers and merchants who own sites for online shops and trading would also benefit, as they can secure or notify authorities earlier on possible fraudulent activities on their card and are backed up with results from the machine learning models. Transactions through the card can then be freezed and ownership can be reclaimed to the original user once more.
System Requirements and Deliverables
The dataset to be used for this proposal is to be obtained from the Vesta Corporation, which is an industry that works alongside the transactions data daily in order to provide the best solutions to use for the prevention of fraudulent practices. The data is derived from the e-commerce transactions and contains several features such as shown below;
| TransactionID | isFraud | TransactionDT | TransactionAmt | ProductCD | card1 | card2 | card3 | card4 |
The test data obtained from the corporation has attributes as shown below;
| TransactionID | id_01 | id_02 | id_03 | id_04 | id_05 | id_06 | id_07 | id_08 | id_09 | … | id_31 | id_32 | id_33 | id_34 | id_35 | id_36 | id_37 | id_38 | DeviceType | DeviceInfo |
This proposal’s implementation aims at testing several machine learning algorithms such as Logistic Regression, Bayesian Methods and gradient boosting algorithms and then compares the performance of these methods using classification metrics such as the confusion matrix.
Since the data is quite large with 1097231 rows and 474 columns, I intend on using the Principal Component Analysis to reduce the dimensions and then encode them so that the available CPU can be able to handle the processing without need for GPUs.
The final output for this project is expected to be a classification results and model validation of the XGBoost classifier because of its speed in highly dimensional environments. This project also aims at carrying out an exploratory data analysis of the dataset.
Primary Research Plan
My research plan in order is as follows;
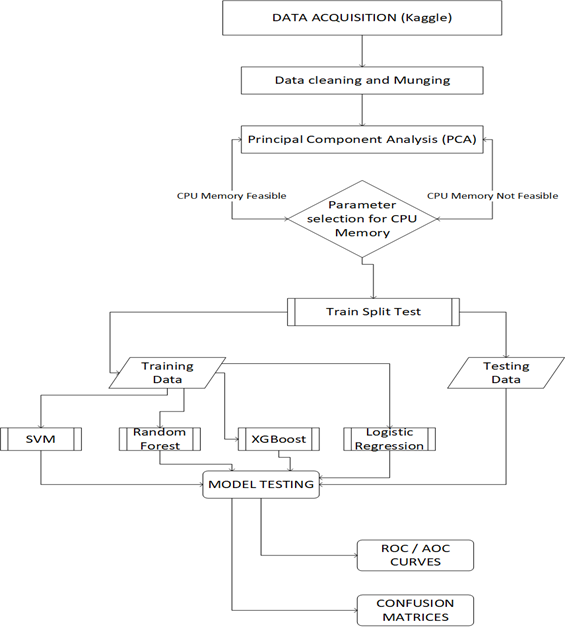
Figure 1 Research plan workflow
My work plan is estimated to take 1 week, including the project implementation and the project write up.
Initial Literature Review
(Sailusha et al., 2020)
In their paper they focus on using two algorithms that is the Random Forest method and the Ada Boost and then comparing their accuracies, precision, recall and F1 scores and the algorithm that performs best is considered for the fraud detection. Their research reaches to a conclusion that the Random Forest classifier performs better than the Ada Boosting for detecting credit fraud. They also suggest that deep learning models and other boosting techniques should be testes and applied for credit card detection.
(Maniraj et al., 2019)
Their paper takes a different approach as compared to the first as they aim for analysing and pre-processing the data sets by reducing dimensions using the Principal Component Analysis and then deploying anomaly detection methods such as the Local Outlier Factor and Isolation Forest methods on the transformed data. The data was then classified as binary such that 0 shows that the transaction was determined to be valid and 1 means that the transaction is fraudulent. The methodology uses only a tenth of the training data and achieves an accuracy of 99.6% but has a lower accuracy of 28%. They suggest that the systems for fraud detection can be improved by including more algorithms into it so that the models can be compared and make more accurate predictions. To be able to deploy such methods in the real world, then the support from financial institutions is key.
(Varmedja et al., 2019)
From their paper, various machine learning methods such as the logistic regression, Random Forest, Naïve Bayes and the Multi-Layer Perceptron are used for credit card detection and then characterizing the methods based on their accuracy of performance. The data used was split into training and testing of the methods after the SMOTE technique was used for oversampling since the data was highly imbalanced. The results from their work also suggest that the Random Forest algorithm performs best as compared to the rest and further suggest that more machine learning algorithms should be tested alongside parameter selection in order to get better results.
(Khare & Yunus Sait, 2018)
Their paper also tests the performance of the machine learning algorithms such as the decision tree, Random Forest, SVM and logistic regression on a highly skewed dataset sourced from 284,786 transactions across Europe. The dataset has to be pre-processed first, on realizing that it is positively skewed and this makes up to 0.173% of the transaction data, the data is transformed using PCA for feature selection and the applied into the models. The results show again here that the Random Forest algorithm performs better than the other algorithms but its speed during the training and the testing is greatly affected. The SVM method suffers more due to the imbalanced nature of the data, in this proposal techniques such as label and feature encoding are to be used so that more algorithms can be tested without the fear of insufficient data pre-processing.
(Fu et al., 2016)
This paper focuses on using the convolution neural networks to capture the fraud patterns learned from labelled transaction data. A feature matrix is used to represent large amounts of transaction data, and a convolutional neural network is used to discover a collection of latent patterns for each sample. Experiments on real-world massive transactions conducted by a major commercial bank demonstrate that it outperforms some state-of-the-art methods in terms of performance. Their methodology is as shown below;
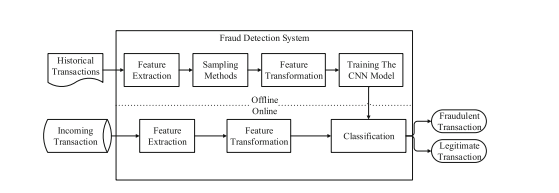
Figure 2(Fu et al., 2016) Credit card fraud detection system
The dataset used for this project was quite large and this meant better learning of the algorithm, despite the absence of comparison with other machine learning models.
(Ogwueleka, 2011)
This research employed the usage of a neural network, a data mining approach. The unsupervised method was used to build four clusters of low, high, hazardous, and high-risk clusters for the neural network (NN) architecture for the credit card detection system. The problem of carrying out optimal categorization of each transaction into its related group was solved using the self-organizing map neural network (SOMNN) technique, because a prior output was unknown. Unlike other statistical models and two-stage clusters, the receiver-operating curve (ROC) for credit card fraud (CCF) detection watch correctly identified over 95 percent of fraud incidents techniques that are state-of-the-art.
The design of a neural networks credit card fraud (CCF) detection model employing four clusters, the design of the CCF detection watch architecture, and the design of the CCF detection alert were all given as part of the research. The credit card fraud detection system was developed using a method that combines traditional data mining and neural network approaches to create a synergy that better handles credit card fraud situations by using four clusters instead of the two-stage model/clusters typically used in fraud detection algorithms. This resulted in a lower percentage of valid transactions being classified as fraudulent, as well as a more accurate and reliable conclusion. The research backs up the validity and effectiveness of ANNs as a research tool and lays the framework for intelligent detection approaches to be employed in a real-world fraud detection system.
(Dal Pozzolo et al., 2018)
Nevertheless, the great majority of purported algorithms for intrusion detection are based on conjecture that are unlikely to hold in a real-world fraud-detection system (FDS). The manner and timing with which supervised information is delivered, as well as the measures used to assess fraud-detection effectiveness, are both examples of this lack of realism. There are three key contributions in this study. First, they offer a codification of the fraud-detection problem that accurately captures the operational conditions of FDSs that analyse huge streams of credit card transactions on a daily basis, with the support of our industrial partner. They also show how to apply the most effective quality metrics for intrusion detection systems.
The researchers next devise and evaluate a unique learning technique that effectively handles class imbalance, concept drift, and verification latency. Third, they demonstrate the influence of class unbalance and idea drift in a real-world data stream with over 75 million transactions approved over a three-year period in their tests. This paper prevents a very intriguing methodology because they simply design their genetic learning algorithms and then go ahead to test them concurrently. The study of adaptive and perhaps nonlinear aggregation techniques for classifiers trained on feedbacks and delayed supervised samples is something that will be pursued in the future.
(Thennakoon et al., 2019)
This study examines four common types of fraud in real-world transactions. Each scam is dealt with using a series of machine learning models, with the optimal technique being chosen through an evaluation. This evaluation gives a detailed guide to picking an ideal algorithm based on the kind of fraud, as well as a suitable performance measure to demonstrate the evaluation. Real-time credit card fraud detection is another important aspect of their product. They achieve this by using predictive analytics powered by machine learning models and an API module to determine if a transaction is legitimate or fraudulent. They also look at a new method for dealing with data distribution that is skewed. According to a private disclosure agreement, the data utilized in their research came from a financial institution. Support Vector Machine, Naive Bayes, K-Nearest Neighbour, and Logistic Regression were chosen as the top four machine learning algorithms.
Regression. They used the supervised learning methods they had chosen to their resampled data using classifiers. When it comes to choosing a machine, the accuracy of learning algorithms that can capture each scam and each model’s performance were considered. The SVM method was found to perform better in this case as compared to the other methods.